
Gathering metrics in Prometheus involves pulling data from providers via agents called ‘exporters’. There are a wide range of pre-built exporters and a range of templates for writing custom exporters which will collect data from your infrastructure and send it to Prometheus.
Node Exporter is the official exporter which exposes a wide variety of hardware- and kernel-related metrics like disk usage, CPU performance, memory state, etcetera for Linix systems. In the context of the following description of installation on a Raspberry Pi, it provides an incredible wealth of information.
Node Exporter
As
node_exporter is an official exporter available from the Prometheus site, and as the binary is able to be installed standalone the installation process is fairly similar. We’ll download it, decompress it and run it as a service.
In the case of the installation below the
node_exporter will be installed onto another Raspberry Pi operating on the local network at the IP address 10.1.1.109. It will pull our server metrics which will be things like RAM/disk/CPU utilization, network, io etc.
First then we will browse to the download page here - https://prometheus.io/download/#node_exporter. Remembering that it’s important that we select the correct architecture for our Raspberry Pi.
As the Pi that I’m going to monitor in this case with node_exporter uses a CPU based on the ARMv7 architecture, use the drop-down box to show armv7 options.
Note the name or copy the URL for the node_exporter file that is presented. The full URL in this case is something like - https://github.com/prometheus/node_exporter/releases/download/v0.18.1/node_exporter-0.18.1.linux-armv7.tar.gz;
Using a terminal, ssh into the node to be monitored. In our case, this swill be as the
pi user again on 10.1.1.109.
Once safely logged in and at the pi users’s home directory we can start the download;
The file that is downloaded is compressed so once the download is finished we will want to expand our file. For this we use the
tar command;
Housekeeping time again. Remove the original compressed file with the
rm (remove) command;
We now have a directory called
node_exporter-0.18.1.linux-armv7. Again, for the purposes of simplicity it will be easier to deal with a directory with a simpler name. We will therefore use the mv (move) command to rename the directory to just ‘grafana’ thusly;
Again, now we need to make sure that node_exporter starts up simply at boot. We will do this by setting it up as a service so that it can be easily managed and started.
The first step in this process is to create a service file which we will call
node_exporter.service. We will have this in the /etc/systemd/system/ directory.
Paste the following text into the file and save and exit.
The service file can contain a wide range of configuration information and in our case there are only a few details. The most interesting being the ‘ExecStart’ details which describe where to find the node_exporter executable.
Before starting our new service we will need to reload the systemd manager configuration again.
Now we can start the node_exporter service.
You shouldn’t see any indication at the terminal that things have gone well, so it’s a good idea to check node_exporter’s status as follows;
We should see a report back that indicates (amongst other things) that node_exporter is active and running.
Now we will enable it to start on boot.
The exporter is now working and listening on the port:9100
To test the proper functioning of this service, use a browser with the url: http://10.1.1.109:9100/metrics
This should return a lot lot statistics. They will look a little like this
Now that we have a computer exporting metrics, we will want it to be gathered by Prometheus
Prometheus Collector Configuration
Prometheus configuration is via a YAML (Yet Another Markup Language) file. The Prometheus installation comes with a sample configuration in a file called
prometheus.yml (in our case in /home/pi/prometheus/).
The default file contains the following;
There are four blocks of configuration in the example configuration file: global, alerting, rule_files, and scrape_configs.
global
The
global block controls the Prometheus server’s global configuration. In the default example there are two options present. The first, scrape_interval, controls how often Prometheus will scrape targets. We can still override this for individual targets. In this case the global setting is to scrape every 15 seconds. The evaluation_interval option controls how often Prometheus will evaluate rules. Prometheus uses rules to create new time series and to generate alerts. The global settings also serve as defaults for other configuration sections.
The
global options are;- scrape_interval: How frequently to scrape targets. The default = 1m
- scrape_timeout: How long until a scrape request times out. The default = 10s ]
- evaluation_interval: How frequently to evaluate rules. The default = 1m ]
- external_labels: The labels to add to any time series or alerts when communicating with external systems (federation, remote storage, Alertmanager)
alerting
The alerting section allows for the integration of alerts from Prometheus. In the default config above there are none set up and conveniently we are going to look at alerting from Grafana instead. So we can safely leave this alone.
rule_files
The
rule_files block specifies the location of any rules we want the Prometheus server to load. For now we’ve got no rules. These recording rules allow Prometheus to evaluate PromQL expressions regularly and ingest their results. Recording rules go in separate files from our prometheus.yml file. They are known as rule files. We won’t be covering these in our examples in this book.
scrape_configs
The last block,
scrape_configs, controls what resources Prometheus monitors. In our default case, only one scrape configuration exists that specifies a single job. In advanced configurations, this may be different. Since Prometheus also exposes data about itself it can scrape and monitor its own health. We can see that in the last line, - targets: ['localhost:9090']. In the default configuration there is a single job, called prometheus, which scrapes the time series data exposed by the Prometheus server. The job contains a single, statically configured, target, the localhost on port 9090. Prometheus expects metrics to be available on targets on a path of /metrics. So this default job is scraping via the URL: http://localhost:9090/metrics.
In our simplest means of adding metrics to Prometheus, we can add additional targts to this list.
Adding a monitoring node to Prometheus
In keeping with the information on the
prometheus.yml file, we can simply add the IP address of a node that is running the node_exporter as a new target and we are good to go.
Let’s add the node that we configured in the previous section at 10.1.1.109.
At the end of the file add the IP address of our new node
- targets: ['10.1.1.109:9100'];
Then we restart Prometheus to load our new configuration;
Now if we return to our Prometheus GUI (
http://10.1.1.110:9090/targets) to check which targets we are scraping we can see two targets, including our new node at 10.1.1.109.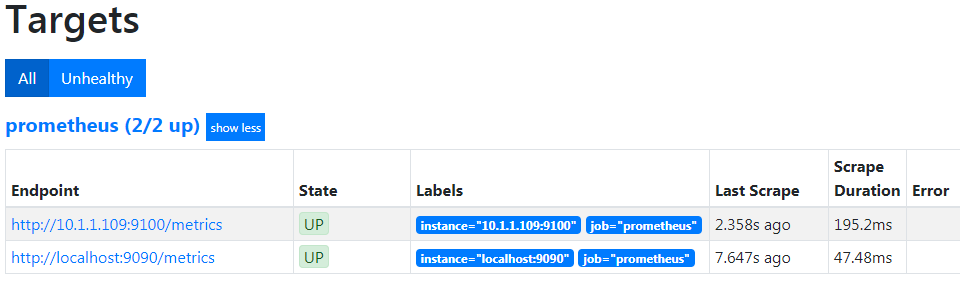
Let’s see our new node in Grafana!
Because we have already added Prometheus as a data source in Grafana, seeing or new node in a dashboard is ridiculously simple.
Go back to our Grafana GUI at http://10.1.1.110:3000.
Select the create icon which is the plus (‘+’) sign on the left hand side of the screen and then select ‘Import’.
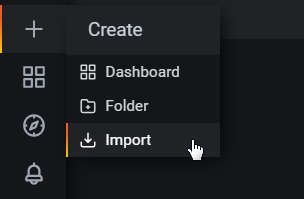
In the Grafana.com Dashboard box enter the dashboard number 1860.

Under the prometheus Option use the drop-down arrow and select ‘Prometheus’.
Then click on ‘Import’.
The dashboard should now be there in all its glory
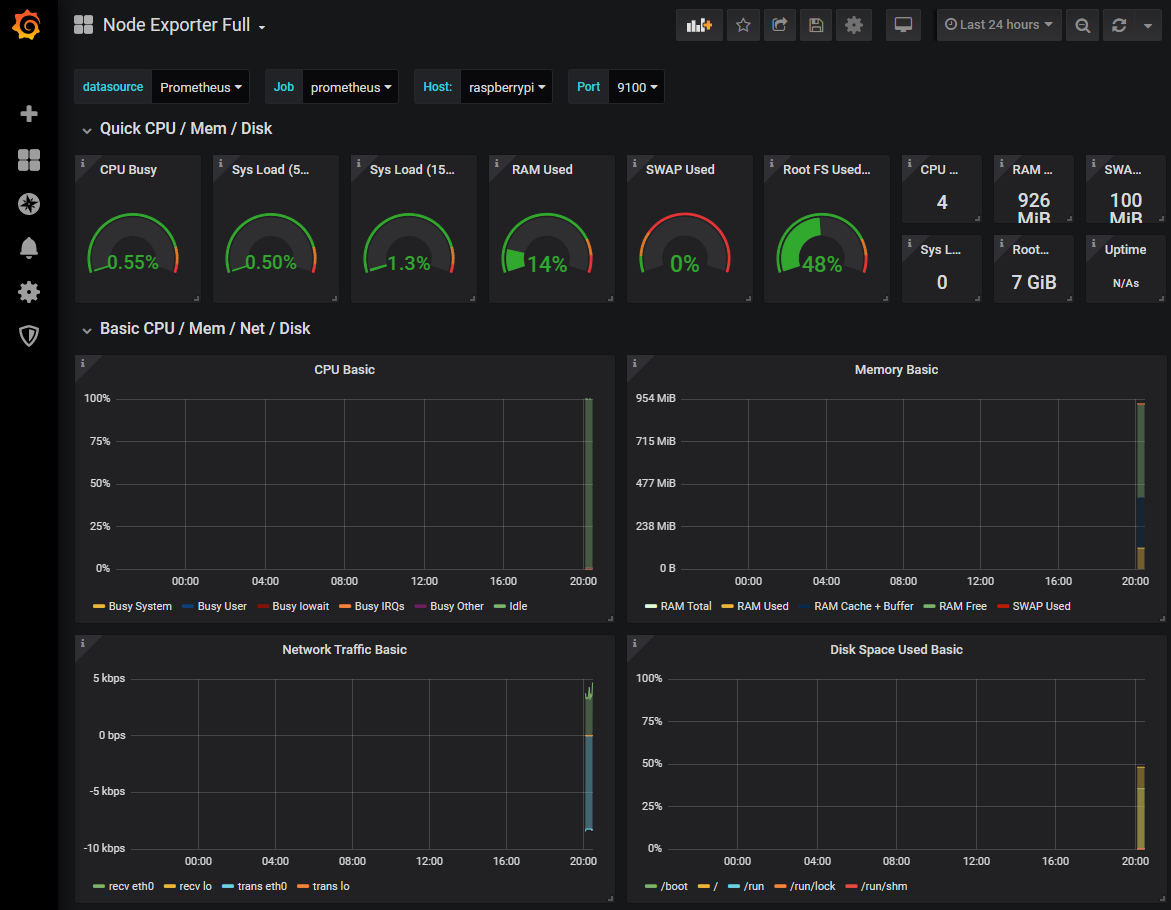
At this stage there probably won’t be much to see, but we can shorten the displayed time to the past 5 minutes by using the custom time range menu at the top right of the screen.
To keep the screen updating select the auto-refresh setting from the top right hand corner. In the screenshot below we are selecting 10 seconds.
The end result is an automatically updating indication of the performance of our Raspberry Pi at 10.1.1.109.
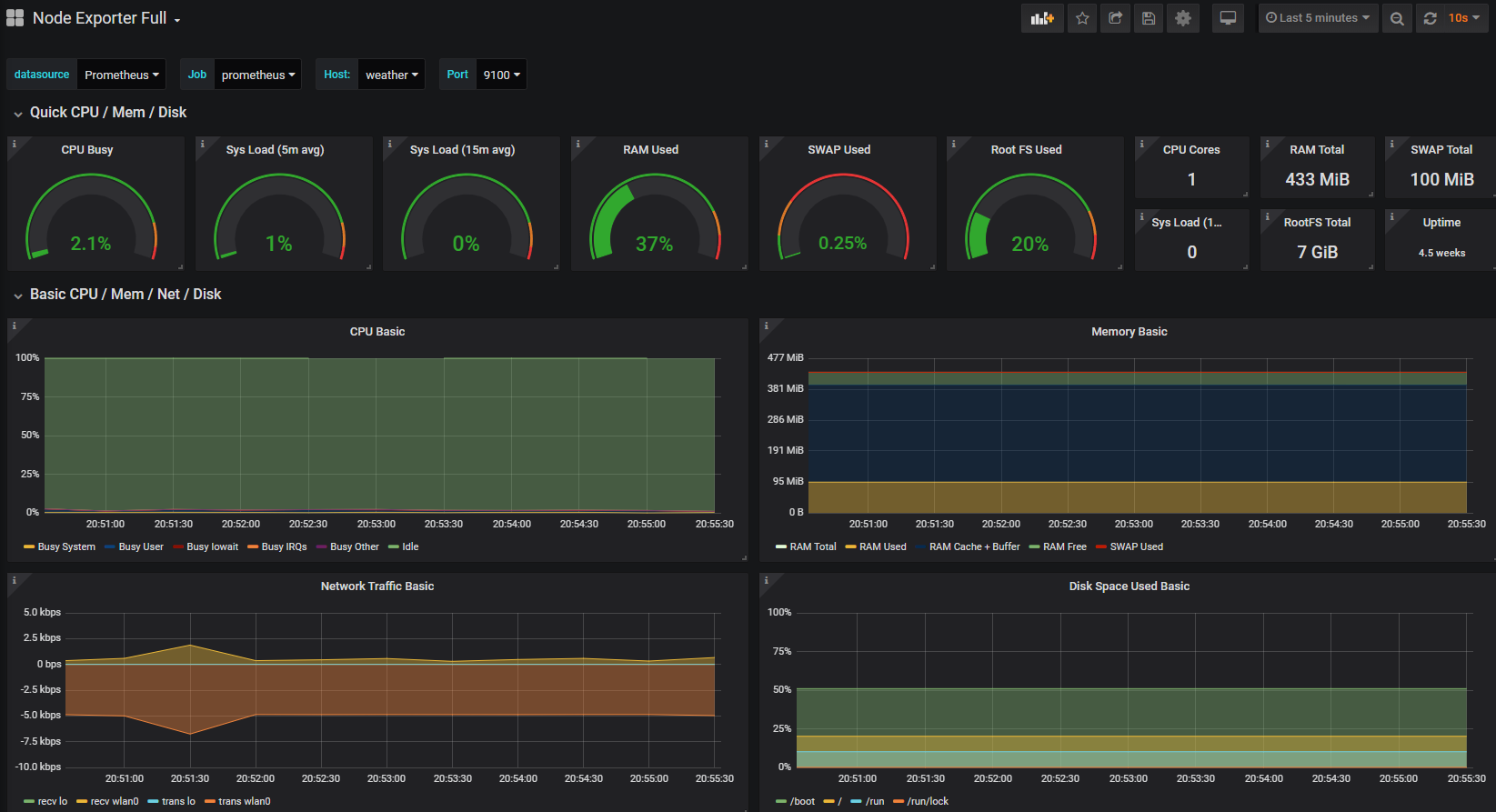
Take a few minutes to explore the additional panels at the bottom of the screen. This is a manifestation of the huge number of metrics that we saw in text form when we tested the scraping of the
node_exporter installation, brought to life in graphical form.
------------------------------------------
Remenber, the decription above of the installation of node_exporter is part of the book that can be downloaded for free here on Leanpub. The full book has a lot more context for the installation.
No comments:
Post a Comment